

By Claire M. Bowen and Evercita C. Eugenio
When middle school students hear the word science, many imagine looking at bacteria under a microscope or mixing chemicals over a Bunsen burner, not writing mathematical equations or typing code on a computer. At the University of Notre Dame, 230–280 middle-school girls (6th through 8th grade) attend Expanding Your Horizons (EYH), an all-day conference to participate in hands-on workshops and activities. The goal of the conference is “… [T]o motivate girls to become innovative and creative thinkers, ready to meet 21st-century challenges.”
The most well-attended EYH workshops involve the more applied fields of STEM—the activities students think are science. As expected, the least popular workshops at EYH are in mathematics and statistics, where students typically learn via chalkboard lectures because creating mathematics and statistics hands-on activities can be difficult for some. Additionally, students have a harder time relating to topics they are unfamiliar with and tend to engage themselves only when the topic is interesting to them. This situation stems from students being introduced to statistics later in their education, either in high school or college. Furthermore, advanced statistics topics that would engage students are generally avoided due to the difficulty of distilling the concept so a younger audience can easily understand it.
In an attempt to create a hands-on activity based on an interesting and advanced topic (data privacy), we designed a statistics activity called Where’s Wenda, named after the female character in the Where’s Waldo books. Since data privacy can be an abstract idea, we want students to imagine that Wenda and all the other people in the Where’s Waldo world are people in a data set. The person trying to locate Wenda can find her based on her iconic red-and-white–striped shirt, despite having several other women with similar hair or skin color in the data set. This shirt is unique and allows the student to find Wenda, just like how an intruder in real life can find someone from an anonymized data set with a few pieces of public information that are also distinctive. In other words, we show students how we can find a person in a data set by knowing what the person shares on social media sites, also teaching the students to be wary of what information they share on the internet.
In general, Where’s Wenda has the following three parts:
- A series of questions about data privacy and other concepts to build an understanding and encourage discussion
- A hands-on activity of finding a person in the data set given information we gathered from social media
- A discussion about what the students learned and what information they should not share on social media
In the following, we narrate how we executed each part of Where’s Wenda at the 2016 EYH, where we hosted the activity three times with an average of 13 participants at each activity session. At the end of this article (Appendix), we outline the rest of the activity with more social media examples. However, we encourage the reader to create their own examples and data set to fit his/her audience (i.e., make data sets that are grade level or interest specific to the class). For instance, since we tested our activity at the 2016 EYH (where the demographic is 6th-8th–grade girls), we used after-school activities such as sports, cheerleading, and musical programs as the content for the social media examples.
Part I: Introductory Discussion
In the introductory discussion, we focused on the main topics of data privacy, identifiable information, and social media. Each topic had two to three questions leading to the definition, instead of stating the definition. For example, the first concept was data privacy. We started with breaking up the phrase to the following:
- “What do you think when you hear the word data?”
- “What do you think when you hear the word privacy?”
- “What do you think when you hear data privacy?”
In addition, we kept the conversation mostly on the students and instigated dialogue by asking further questions. This style of teaching is most commonly known as the Socratic Method. For instance, we led the discussion on what data is, similar to the following:
Teacher: “What do you think when you hear the word data?”
Student: “Numbers.”
Teacher: “Yes, data has numbers. But, if we asked everyone what their favorite class is in school, would that be data?”
Student: “Yes.”
Teacher: “Is that a number?”
Student: “I guess not. I guess data is anything we know about a person.”
Teacher: “Yes, data can be any kind of information about someone or something.”

In addition, we recommend the reader keep the ordering of questions we listed in the Appendix. Overall, in the three EYH workshops, the students gained a better understanding of data privacy, identifiable information, and social media.
Part 2: Interactive Activity
After covering the main concepts, we started the interactive part of the activity with students broken into small groups. Each student was given a printout of the example data set and the activity scenarios (Appendix). We told the students we would show them how an intruder can identify someone with unique, personal information—like Wenda and her red-and-white shirt. This time, however, rather than choosing someone out of a picture, students would use the data set and information from social media to find the unique person.
The following are some scenarios we guided the participants through at EYH. We used a projector to show the example data set and marked it with a dark marker so students could follow along easily.
Solution Scenario 1: Prior to finding the solution to this scenario, we asked the students if they were familiar with Reddit and if any were users of the site. This ensured the students understood Reddit is an online social media community that allows users to vote on content and that there are many subreddit groups users may create. From this, we asked the students what information they could gather from Scenario 1. Based on the different subreddits included in the scenario, the students determined the user had some interest in basketball, football, math help, and sprint. This is the information we had the students use to narrow down the example data set.
As the first subreddit listed is r/basketball, the students assumed the person participates in basketball. Therefore, they were able to narrow down the data set to six people (ID = 3, 4, 5, 7, 13, and 15), as those are the only people who participate in basketball.
Second, the user posted in r/football, so the students assumed the person participates in football. Once again reviewing the example data set, the students found there are only four people who participate in both basketball and football (ID = 4, 5, 13, and 15).
Third, the user posted in r/mathhelp, so this led us to assume the person of interest may be struggling in math. Based on this information, the students determined they were most interested in the variable ISTEP (Indiana Statewide Testing for Educational Progress) Math score in the example data set, since it is the only variable that deals directly with a student’s math ability. Thus, because the person is looking into getting math help, we could assume their ISTEP Math score might be lower than the others. Observing the ISTEP math scores of the four people who play both basketball and football, there is only one person who struggled on their math ISTEP (ID=4). The other three people all scored above a 600 on the math ISTEP, while person ID=4 scored 370. Thus, the students concluded they believe the person of interest is ID=4.
To confirm this conclusion, we used the fourth subreddit of r/sprint to see if ID=4 participates in track/cross country. Looking at the example data set, this is indeed the case. Therefore, with the knowledge of the subreddits the person of interest posted in, we were able to determine their identity.
Person ID=4 is a 7th-grade male whose race is other and he has four siblings, scored a 370 on the math ISTEP, and scored 520 on the reading ISTEP.
Solution Scenario 2: This second scenario deals with Twitter, so we began the discussion by asking students what they knew about Twitter and what they often share on Twitter. This allowed students to think about everything they share on social media. From there, we discussed what information was given in the scenario. The students decided that, based on the Twitter tweets by Jacob Li, the following information available is the following:
- The Twitter user’s first name is Jacob, so likely the user is a male.
- The Twitter user’s last name is Li, so likely the user is Asian or could be Other.
- The Twitter user posts about making the basketball team, so we know they participate in basketball.
- The Twitter user posts about Science Bowl, so we know they are a Science Bowl participant.
- The Twitter user includes the hastag #honors, so likely they are a member of the National Honor Society.
Using all this information from the Twitter tweets, the students narrowed down the data set to identify the person of interest. As Jacob is a male, only those with ID = 1, 3, 4, 5, 8, 13, and 15 could be Jacob. Jacob is also either Asian or Other, so based on the seven males in the data set, only ID = 3, 4, 5, and 8 could be Jacob. Of the remaining four people in the data set, only ID = 3, 4, and 5 participate in basketball. Then, of the remaining three people in the data set, only one person (ID=3) participates in the Science Bowl. Further, ID = 3 is also a member of the National Honor Society.
Based on the information learned from Jacob’s Twitter tweets, the students identified him as person with ID=3 in the data set. This means, we know Jacob Li is an Asian male in 8th grade with no siblings who scored 800 on the math ISTEP and 770 on the reading ISTEP. We also know he participates in basketball, the Science Bowl, and the National Honor Society.
After demonstrating how an intruder identifies a person in a data set, we assigned each group with Scenario 3, 4, 5, 6, or 7 and asked them to try to finish in 10–15 minutes (all additional scenarios are in the Appendix). If the group completed the assigned scenario with time remaining, we encouraged the students to attempt Scenario 8, which produced two potential solutions. Once time was up, we asked each group to present their solution in front of the class, instead of just providing the answer. We wanted the students to practice presenting in front of other people, since this is a critical skill many adults struggle with.
Once all groups presented the solution for their assigned scenario, we asked the class what they thought the solution to Scenario 8 was. We received various answers and told the students that several of their answers were correct, but we could not be certain who exactly the person of interest is in reality. We outlined Scenario 8 as follows:
Solution Scenario 8: This scenario demonstrates that an intruder does not always identify a single person of interest. We began by asking the students what information they could get from the pins on Pinterest. The students collected the following information:
- Jordan could be a boy or girl. We are not clear about the person’s gender simply based on their name.
- Since there is a picture of books with a quote about reading, this person likely has good reading skills or a strong interest in reading.
- As the second picture is about hockey tickets and happiness, this person likely is involved in hockey.
- The third picture is of a science activity about frozen dinosaur eggs, so likely this person is involved in the Science Bowl.
Thus, based on all this information, the students narrowed down the data set. Since this person is likely in both the Science Bowl and hockey, there are only two people in the data set that participate in both (ID = 8 and 14). Then, observing the ISTEP English score for each person, the scores are 820 for ID=8 and 690 for ID=14. While 820 is a very high score for the ISTEP English, a score of 690 is high as well. Therefore, some of the students concluded that either ID=8 or ID=14 could be the person of interest because they both satisfy the information gained from the scenario.
We initially incorporated Scenario 8 to demonstrate that even if an intruder has additional information, the intruder is not guaranteed to identify a single person in a data set. However, some students had difficulties understanding that an intruder is not guaranteed to find a single person in a data set. This misunderstanding most likely arose from repeatedly showing through the first seven scenarios how an intruder could identify a single person in a data set. When executing this activity again, we plan to either include a new discussion in the activity that talks about this issue or remove it entirely to focus on the other concepts.
Part 3: Final Discussion
Last, we wanted students to learn from the activity that they should be cautious about what personal information they and other people share. We asked the following questions:
- What kind of information would you not share?
- What kind of information would you be okay with sharing?
- What else did you learn?
Overall, many students commented about how surprised they were that an intruder could identify a person in an anonymous data set so easily. We also found that some students started to really think about the things they were sharing on social media and the simple ways they could be compromising their privacy.
After the initial discussion, we provided specific examples of how social media could be used for malicious purposes. For instance, family or friends tagging people on Facebook with a location or posting vacation photos while still away from home can potentially be dangerous. An intruder could use the public information to stalk the individual or rob the individual’s house while the family is vacationing. We found several news articles describing similar instances (described in the Activity Outline in the Appendix) and advise the reader to update articles regularly for relevance.
Understanding the possibility of personal information being used, we encouraged the students to think more critically about what information they shared through social media and to talk with their parents about the topic. Furthermore, we reviewed types of information that could lead to identification that may not be important to middle-school students, but would be when they become adults—birthdates, birth places, and personal medical information (full list of examples in the Activity Outline in the Appendix).

While we had great success with our activity, we have suggestions for future modification and consideration if the reader plans to implement this activity. First was the confusion with Scenario 8, as described above. The other problem we encountered was “scaring” the students too much. Although we wanted students to be wary of what personal information to share, many students became scared that they had shared too much already or thought they should never use social media. Realizing this issue, we talked about what information we can share that is safe. For example, only posting vacation photos after returning home from the vacation would be a good alternative to posting vacation photos while you are still away from home. Overall, the students found this statistics activity to be highly engaging and pertinent to their lives.
Appendix
Activity Outline
We designed the following activity to teach students about data privacy and confidentiality. The activity is broken down into three sections, and detailed instructions are provided. This activity is intended for class sizes of no more than 24 students and should last 40–50 minutes. Teachers who implement this activity can control the time length by allowing discussions to last longer or shorter as needed.
Introductory Discussion
Students will be introduced to the main topics of data privacy, identifiable information, and social media. The teacher(s) will lead a discussion that includes the following questions. Asking these questions in the order listed will ensure the students have a clear understanding of the main ideas before moving to the interactive part of the activity.
What is data privacy?
- What do you think when you hear the word data?
- What do you think when you hear the word privacy?
- What do you think when you hear data privacy?
What is identifiable information?
- What information do you think could identify a person?
- What information on the internet could identify a person?
How do you share information online?
- What social media do you use?
- Do you think you share information that identifies you?
Interactive Activity
By numbering off, students are divided into groups of three to four students. The random assignment of groups will encourage students to work with peers they may not normally interact with. Additionally, groups are kept to a maximum of four students.
Students are each given a printed copy of the data set, and each group is given a printed copy of the activity scenarios.
The teacher(s) will go over scenarios 1 and 2 as examples so students understand how an intruder might identify someone in an anonymous data set.
Groups will work on the remaining scenarios for 15 minutes. Each group will be assigned a scenario in which they will be expected to present the solution to the rest of the class. If there are more scenarios than there are groups, then scenarios should be assigned beginning with Scenario 3 and the entire class should solve the remaining scenarios. Students should first complete their assigned scenario, and then, if time permits, work on the other scenarios (unassigned first if there are any).
For each scenario, the assigned group must present their solution step by step to the rest of the class. Upon completion of each group presentation, the teacher(s) will pose the following questions about the specific scenario to the entire class:
- Did you use all the information given in the scenario? If not, what information was unnecessary to identify the person in the data set?
- Was there a piece of information that seemed to really narrow down the data set?
- If the final solution did not identify a single person, but instead two or three or more people, was the data set at least reduced?
Unassigned scenarios should be solved with the entire class working together. For any unassigned scenario(s), the teacher(s) will lead the class in a discussion about how to solve each. The teacher(s) should not immediately give the solution to the students, but instead allow the them to provide each step of the solution.
Final Discussion
Upon completion of the interactive activity, the teacher(s) should ask the students a series of questions to see what they have learned. This will allow the students to relate their activity to their own understanding of privacy and social media.
- What kind of information would you not share?
- What kind of information would you be okay with sharing?
- What else did you learn?
Examples (i.e., birth dates, medical information, and driver’s license information) illustrating how data privacy can be breached based on seemingly innocent social media posts are then presented to the students. These examples should help the students understand that posts they may think are harmless could be combined with other information about them to lead to serious problems.
Finally, students should be presented with a list of important information they should not share publicly, similar to the following:
- Birth Date
- Birth Place
- Passport
- Driver’s License
- Credit Cards
- Social Security Number
- Medical Records
Further Example Scenarios
Scenario 3: Cathedral Jr. High School posts on their public Facebook page a picture of the girls cheerleading and dance squad with the caption “1st place Stunt Group. 1st place Pom. 1st place Sideline. 2nd place Show. District Champions. Academic Award.” A parent replies and tags the girl on the first row, far left, and comments with “So proud of my girl! She also made the Cathedral Jr. High School Academic Honors!”
Scenario 4: A Pinterest user has the following kinds of pins:
- A picture of a girl competing in the high jump
- A picture of a cello with the caption “Keep Calm and Play Cello”
- A picture of a child playing chess
- A picture of an ad for an “A-Line Sweetheart Neck Prom Dress A>”
Scenario 5: A Reddit user posts in the following subreddits:
- r/Lacrosse
- r/Womens_lacrosse
- r/choir
- r/correctmygrammar
Scenario 6: A middle school posts on Instagram a picture of some of their band students with the caption “#regionalchamps #irish #clarinet #bestmiddleschoolband. In the comments section, a parent posts “So proud of my eldest daughter.” Replies to the post include the following:
- Walter: “I LOVE U SWEETHEART!”
- Janet: “WOW! Such a talented young lady!”
- Alice: “I know! Not only is she musically inclined, but also book smart!”
Scenario 7: A YouTube user, VolleyballGirl2000, comments on different videos.
- Video of a cheerleading routine posted by the local high school
- “Way to go big sis! I am so proud of you!”
- Video on running tips
- “This is totally what my coach makes us do!”
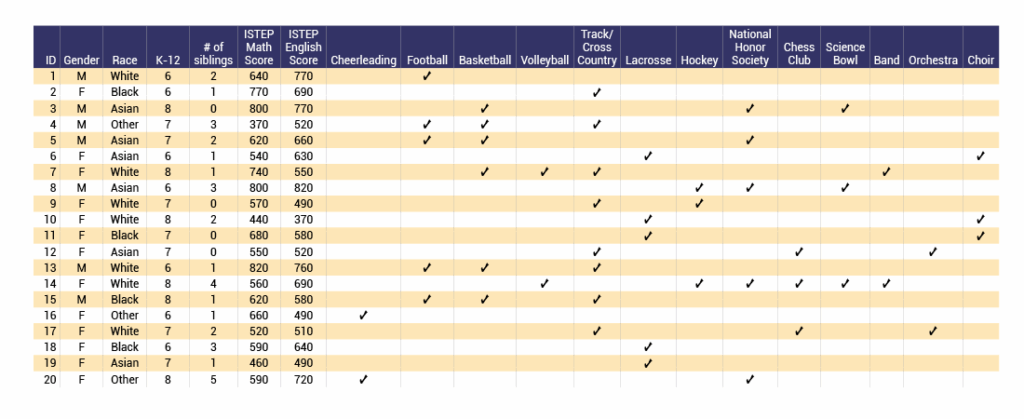
(Download the example data set.)
Published Articles About Location/Daily Routine
- “Facebook ‘Nearby Friends’ Will Track Your Location History to Target You with Ads‘”
- “Here’s How Anyone Can Stalk Your Exact Location Using Facebook Messenger”
Published Articles about Vacation Posts
- “Facebook Status Update Leads to Robbery”
- “Facebook Vacation Post Leads to Break-In Gun Theft, Oklahoma Deputies Say”
About the Authors: Claire M. Bowen and Evercita C. Eugenio are graduate students in the department of applied and computational mathematics and statistics at the University of Notre Dame.
Leave a Reply